I was fortunate this year to attend the AWS Summit at London's ExCeL. In this post I wanted to outline what the event was like (for a first timer), what I learned and other tips I found.
What it was like
The conference itself is enormous. Over 25,000 people all flocked to the ExCeL in London to worship at the alter of Werner Vogals - I mean talk about all things AWS. It was good being surrounded by people who worked on similar things to you.
There are two key parts of the summit - the talks, and the vendors.
Overall, the talks were great. I think your experience depends largely on what talks you attend. From speaking to my colleagues who attended other sessions that the "difficulty" ratings for the sessions do not represent the actual technical detail they provide. There are a few categories of talks
- Talks from a company representative describing how they use a particular AWS technology. Usually these talks have 2-3 speakers - with 1 coming from the company in question and the others from AWS themselves. For example, I attended a talk by Flo Health who had their CTO speak about how they were using DynamoDB to store data in their system. They then had 2 AWS representatives give talks about how DynamoDB worked under the hood and cost optimisation strategies. These were the best talks to attend in my opinion.
- Talks sponsored by a company. These are more like sales pitches to demonstrate how you can use a companies technology.
- Talks by AWS themselves. These are usually focused on a particular area or AWS service. I found these to be very high level and to "drink the coolaid". For example, when speaking about analytics for serverless systems they of course recommended Cloudwatch (which is terrible). And for increasing resiliency recommended Blue/Green deployments with Codebuild (which is trash).
- Community talks. These were likely not recorded so are valuable to attend in person. I attended one of these in the morning and found it to be like a talk you might find at a good tech meet-up.
The vendors are a sprawl of booths that litter the conference floors. They are different software companies of all flavours advertising and pitching their products. They usually give away swag of some description (I got a bucket hat from PagerDuty) and some have challenges where the winner gets a prize. These challenges usually have huge queues so I avoided them and focused on what I could get out of the experience as a whole.
What I learned
I was able to attend 4 talks in total here are my learnings from each.
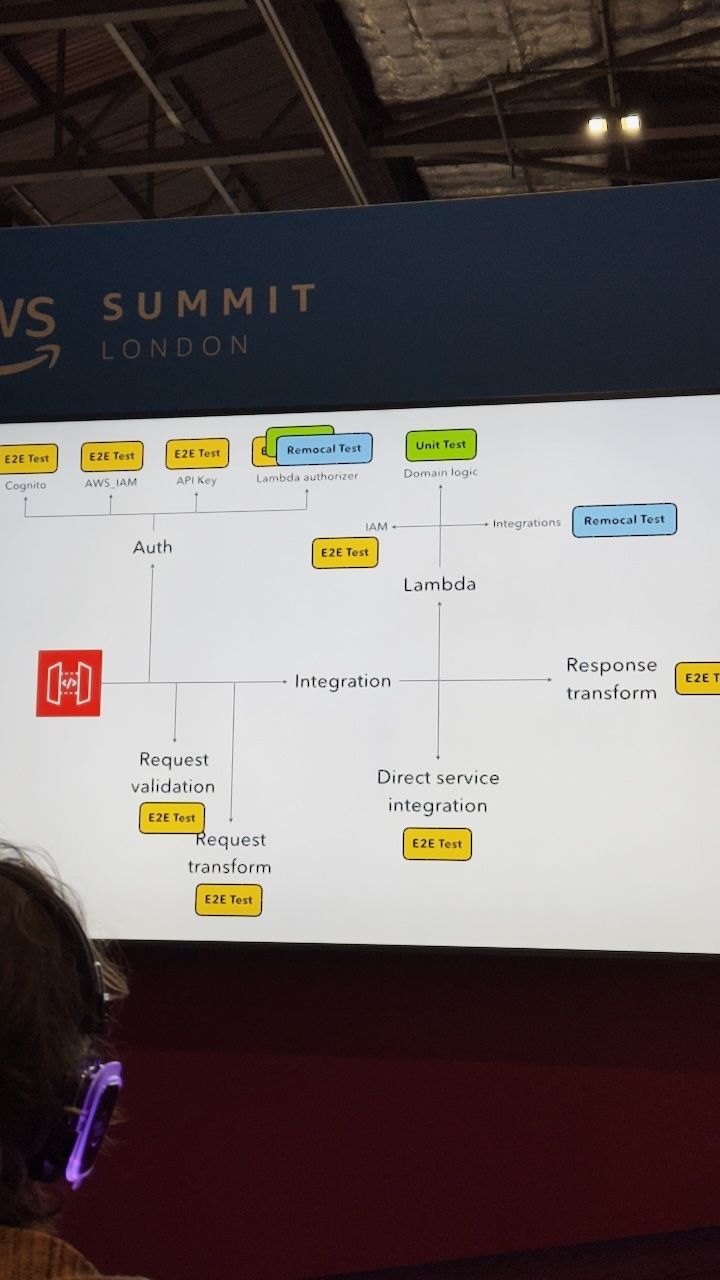 "remocal"
"remocal"
"COM201: Patterns for Efficient Software Architecture"
- Focused on local development for serverless.
- Use Lambda to transform data NOT transport data
- Try to leverage no code serverless solutions where possible for transport - event bridge pipes, dynamodb streams etc.
- Suggested strategy for local development and testing is "remocal" - a portmanteau of "remote" and "local"
- This entails testing against mocks and true resources (deployed into AWS).
- So you deploy your code to an ephemeral environment. And then write tests that use mocks for DynamoDB responses but then call the actual API gateway (for example). This is targeted at testing and debugging the code in the Lambda's themselves.

"ARC302: Building observability to increase resiliency"
- One pain point that many businesses face is there is no granularity to the errors they get - for example "the site is down".
- The key to resolving this is multi-dimensional errors - for example "latency per trace id", or "requests per AZ" etc. This can all be provided by Cloudwatch.
- Increased observability can then feed into automated rollback systems. The multi-dimensional alarm would be "errors per code revision" for example.
- JustEat engineer spoke about how:
- They regularly have engineers review logs for noise. I think this is a good practise but difficult to understand what is noise.
- They standardise labels across their services - environment, service, team and version/code revision
- These tags feed into cloudwatch alarms which help them to detect bad deployments etc.
- Teams have regular "graph club" meetings where the goal is to understand and review telemetry data and action any monitoring and alerts.
- Game days are recommended to be done on a regular cadence. A good game day is described as
- Realistic - like production if possible
- Reasoned - having a why and desired outcomes
- Regular - with a regular cadence.
- Controlled - targeting a certain system or area. For example, how do our API's react without database access.
- Tools such as AWS Fault injection service can be used to facilitate these game days.
- They brought out a good illustration (which I foolishly didn't note down) where the idea was that you practise to build your own luck. In this context, they were talking about how it could be viewed as "lucky" that justeat rarely goes down. But the reality is that they practise the system breaking so much that they never face it in production and if it does, they know what to do to fix it quickly.
- The final note was to have an observability strategy. This should align with the business goals. It's not just a case of saying "more metrics, more alarms" but knowing what to measure and why.
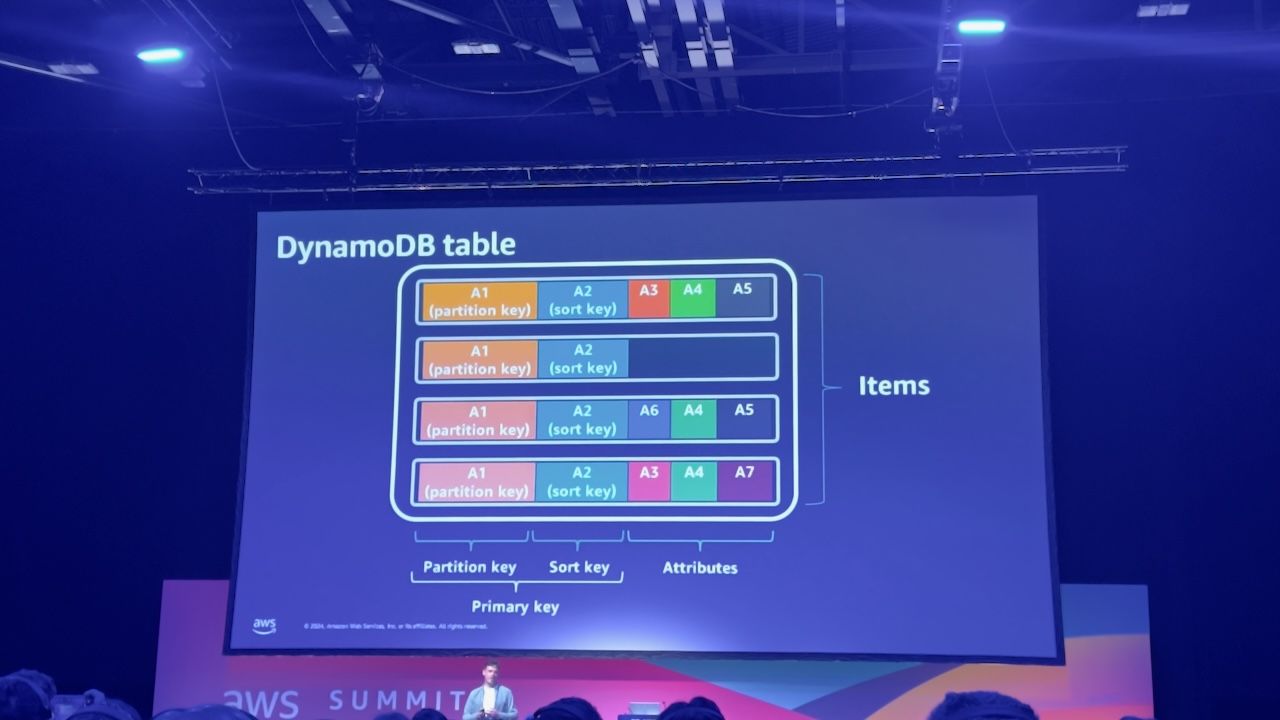
"DAT202: DynamoDB Deep dive with Flo Health: Powering critical data for 300M users"
- Data for their customers is very sensitive as it's around reproductive health.
- They also had the challenge of scaling to large user numbers without increasing costs. Uniquely they give their app away for free in 66 countries where education and help is needed but income levels mean they couldn't afford a subscription app.
- One of the main challenges for them is that all the data is unique, specific and needs to feed into a personalised experience. They describe storing over 1 trillion data points - all in DynamoDB.
- Their PII data is triple encrypted - using AWS KMS, the default server encryption from DynamoDB and encrypting the data itself at an application level.
- Under the hood of DynamoDB, and how it scales so well, is that each partition is provisioned with 1000 write units, 3000 read units and is up to 1GB in size. They can scale these partitions limitlessly.
- To partition data, they hash the partition key.
- Each GSI is like a materialised view and a different version of the database under the hood.
- Sometimes it's ok to throttle! For example, if something is inserting data to DynamoDB from the back of a queued job it doesn't matter if the insert gets throttled because it's not customer facing. So you can more freely use provisioned access because the impact is low. On the other hand, favour using on demand for customer facing tables.
- 1KB = 1 WCU. Therefore the max consumption is 409,600 Bytes = 400WCU - because the max item size is 400KB.
- This means increased item size = bigger costs. If you want to update a single attribute in a 400KB item, you used 400WCU - because there is no such thing as an update with DynamoDB - it's a delete and insert.
- The recommendation therefore is to "vertically partition" your data. This is the push of the single table design model. Where the sort key is used to differentiate different properties of data related to a single partition key entity.
- This reduces cost by only having to access or update smaller records. Lots of data changes infrequently so doesn't need to be updated much and can be collected together.
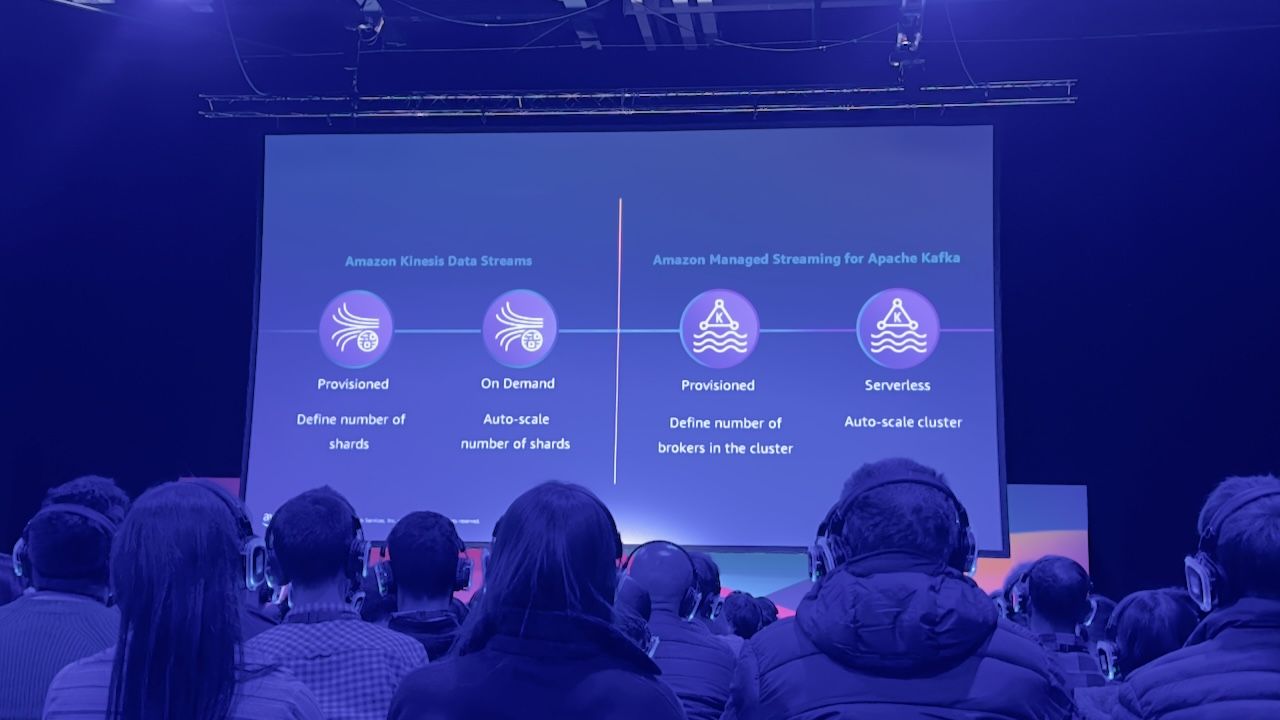
"ANT306: How the BBC built a real time media analytics platform to process over 5B events a day"
- The BBC talked about their unique challenges with data
- Multiple platforms - weather, iplayer etc.
- Needing to provide real time feedback to customers.
- Data has a "half life" of usefulness - meaning the longer it takes to provide insights to that data the less useful it is to a customer. A recommendation to watch a program 40 minutes after they have finished the last program is not useful.
- Primarily they use Kafka, Kinesis and Flink.
- They developed an SDK which abstracts the analytics data gathering from developers. This allows for consistent data gathering across all their products.
- They initially used timestamps sent from the clients to dictate when an event occurred. This led to issues with data processing (due to processing data by time chunks), so they switched to the timestamp when Kafka received the event.
- There other issue was with bad or malicious data. Using JSON schema definitions, which power their event system, they were able to tighten these definitions and dead-letter any events that were bad or malicious.
- They chose JSON schema's (over protobuf etc) because of compatibility with existing API's as well as compatibility with tools like Kafka and Kinesis. In particular it allows them to make no-code changes when a new event gets added to their platform. The definitions get stored in S3 and then registered by Kafka.
- The final problem they described was how they distribute Flink tasks (machine learning)
- If they do random then it makes querying for time specific data very memory intensive (for example "unique readers in the past 5 minutes").
- If they do it by articleId they often overloaded one Flink instance. This was because people would view a single page on the website and refresh lots - for example when the champions league was being drawn.
- In the end they chose to accept a certain level of inaccuracy and went with a system called HyperLogLog. This is an algorithm for calculating high cardinality with minimal memory usage.
Other tips
- Plan your day in advance, ideally to things that are close together. If you have to walk around a lot of the centre to get to your next talk then you might not get in as there are always queues to the great talks.
- Allow space in the day to talk to vendors. Target both those that you (or your business) are using and see if they have any new features/releases coming up. For vendors that you don't or haven't used, approach with curiosity and have an idea of where you might want to use them.
- Most of the activities and challenges have huge queues, I personally avoided these because it cut into time doing other things but YMMV.
- Registration is listed from 8am-10am. My train was late so arrived late and was surprised to see hoards of people still queuing for the registration.
- Lunch is provided but there are plenty of (overpriced) options in the excel centre.
- Unless you want to do a workshop or take notes, then you can leave your laptop at home.
- Usually there are drinks at the booths between 4:30 and 5:30.
- Although I arrived late to the keynote, I don't think I missed much. It really just outlined the day. It also is recorded and available online. I'd recommend using the time to explore the venue and talk to vendors.
- Download the Map, your agenda and anything else you might need to your phone in advance. The wifi is quite spotty and there is barely any phone signal.
Overall, if you have the opportunity, I'd highly recommend attending. It's well worth it, even if just for the stickers.
{kind=link}