Your boss has just got off the phone with a client who wants a bespoke social network site targeting a niche market. And they want you to head up the project. You’ve never built a social network. Your mind goes to Facebook, Twitter, and Instagram. They’re built by thousands of people with genius level IQ’s and degrees. How could you compete?
Well that’s at least the situation I found myself in.
My task was to first to design a database for this social network client. This is the advice and help I would have wanted to read. Please note: This applies generally for all database design. A social network will be merely used as an example.
But why did I feel that the database design was so critical?
-
Bad database design leads to laborious and slow queries
-
Duplicate data and incorrect column data types occupy more disk space
Think about your features and the relationship between them
What are the features of the site? Really break it down. The more you break it down, the less “Oh yeah, let’s add a table for that” you’ll get later down the line. I suggest using a tool like draw.io to map out your tables before putting them into the actual database.
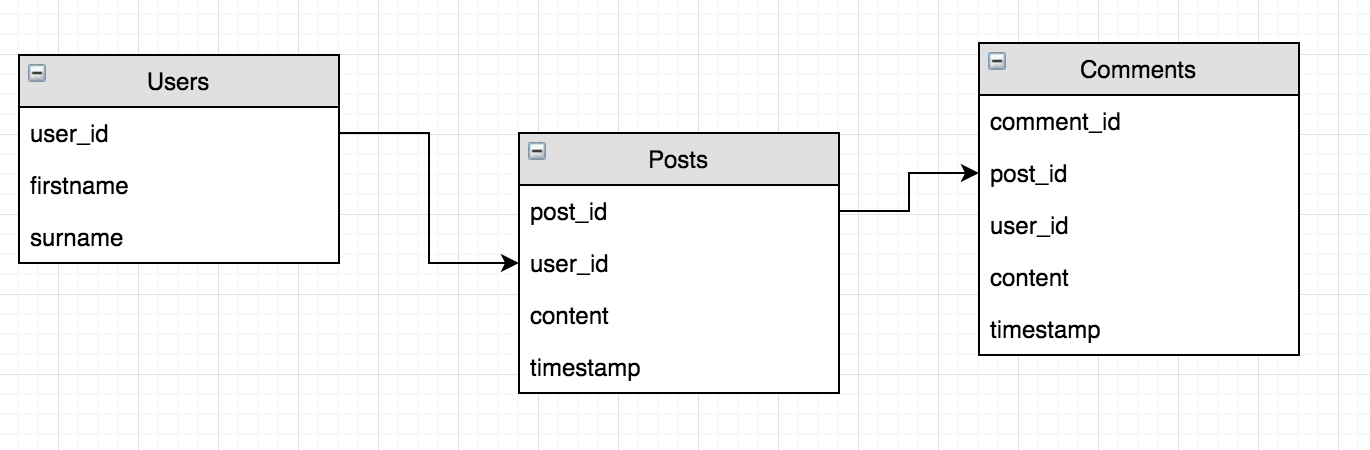
As we are building a social network, the leading feature is letting users posts and allowing other (authorized) users to comment. Here we have a one-to-many relationship, because a user will be able to have many posts and comments.
We will have other instances such as with user “likes” (such as liking a page, or group) that will require a many-to-many relationship because a user will have many likes, and those likes will have many different properties.
One of the primary objectives of good database design is to remove redundant data and increase the integrity of that data. Often, people combine tables that have one-to-one relationships. For example storing users data with their address. Let’s see why:
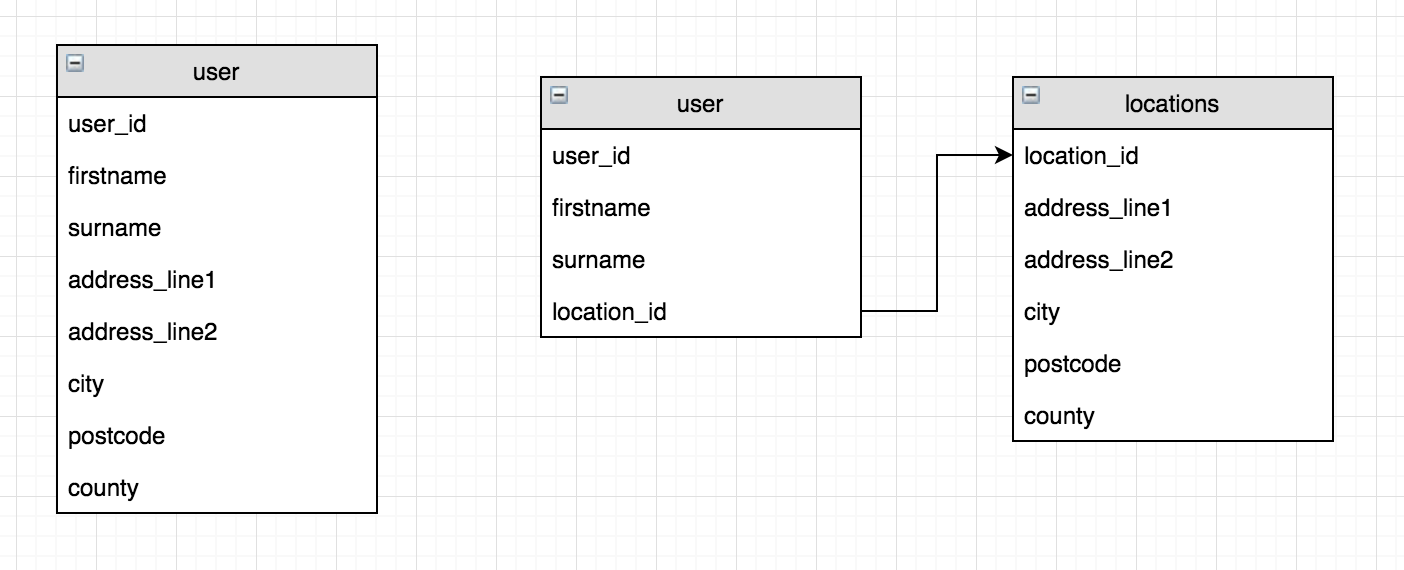
The example on the left combines the users table with the address for that person. On the right we have separated it into different tables. But which approach is optimal?
Well, as with most things, it depends. When I was building this particular application, the address was an optional field, therefore it was most appropriate to store these locations in another table. Furthermore, it was under future consideration to allow for many addresses for a single user. Therefore, in my case, storing them in the same table would restrict me to a 1-to-1 relationship only, thereby limiting me on future features.
Performance may be a factor here as the more “relationship” tables you have, the more joins you need to make, thereby slowing query time. This could have repercussions as you scale.
Think about what data you will need
That leads onto my next point about think through what your application will display. Think about the query to get that data in your head. If, to extract that information, you have to make tons of joins and subqueries and all sorts then perhaps you need to rethink your design.
I’m most keenly aware of this principle when thinking about analytics. For example, in this social network application, we want analytics for where the application is used. If we are to do this purely via the address fields we store for users (without any IP location wizardry) then we may chose to store the counties list in a separate table and then link that with the main addresses table. This would enable us to quickly query for certain countryid’s and ascertain how many users are registered there. We _could leave the country as a text input for the user but this may lead to incorrect spellings of counties and other duplicate data that would lead to false statistics.
Overall, understand what your application requires and design around that whilst still being flexible for future expansion.
Think about the data stored in the columns
An underestimated point of database design is that of column data types. Often columns are given simple VARCHAR or INT data types, this is not always the most performant or memory efficient way of designing them and changing the data type after the fact can lead to corrupted data in those columns.
Become familiar with the different data types, these are almost universal across all programming languages and databases and will allow you to think at a lower level of abstraction to the data you are handling.
As mentioned previously, one of the main problems with inefficient data types is that they occupy too much space on disk. For example, let’s say we are storing a flag checking if a users post has been deleted or not. Because the only 2 values of this column should be 0 or 1 (the former for undeleted, and the latter for deleted), then we do not need the 4 bytes it takes to store a whole integer (which can be any number from -2147483648 to 2147483648). We merely need the TINYINT data type (or BOOLEAN in MySQL), which occupies a mere 1 byte. That’s a whole 4 times smaller! Now 4 times smaller than nothing is still nothing so this may seem like a needless reduction that will save a fraction of disk space. And in most cases, you are probably right; But if the service were to scale, to hundreds of thousands or even millions of rows, then your boss would be thanking you for saving them a lot of money in drive space by going for the TINYINT option. Take the time to think of the most performant and lean design for your database. Act as if you are designing for Facebook-level scale — it will pay off.
Avoid storing calculated columns
A common mistake when designing a database is to store redundant information that can be calculated by your application. Using my example, we want to display the users age on their profile. It may be possible to store the users age directly in a column, but if we have their birth date then we can simply calculate their age on the fly. If speed becomes an issue where calculations cannot be done, then it would be best to cache it in your application or in a key-value database such as Redis before finally resorting to storing the calculated value. Other examples of where calculated information storage might be suggested is for exam grade averages or the number of orders a person has placed.
What other tips do you have for database design?
I tried to target the “Pareto problems” here — meaning that, in my view, these 20% of tips will solve 80% of basic database design problems. That being said, there is a lot more to learn, and if you’re interested check out database normalization rules (NF) once you have fully taken in the information from this article.
👋 I am available for hire as a freelance application consultant/developer. Contact me at [email protected] if you would like to discuss any projects you have in mind.