Resiliency by design in your products architecture is a challenging problem that is rarely tested. Building robust platforms are becoming increasingly important as large server providers such as AWS start to show their cracks in addition to good old fashion human error (we had an engineer take down a server by knocking it with his ass). Chaos monkey and other tools have sprung up to pursue down resiliency issues, but despite this, they can still persist. Here are a few things to look out for when designing a new system or analysing existing ones.
Backing Off
Your app tries to contact a critical external service, maybe it’s your database, or perhaps a 3rd party API — whatever the case, it **will **fail on you. A common way to handle this is by setting a timer to retry the call to the service. At CloudCall, we have a stateless service to handle sending SMS messages, whenever it cannot save the message to the DB or send it to our SMS provider (or they return an error), we automatically requeue the message for a set time in the future. If we get the same failure the next time around, we requeue it again, this time for a bit longer and so on, until we get a success.
You may not think this is possible in the world of serverless — but it is! In AWS Lambda, if you throw an exception or use context.fail() then the lambda will retry up to 3 times before giving up. Although with this setup you cannot have the gradual back off, you are still getting the beauty of the retry. However, if you setup the Lambda with SQS you can also configure the lambda to DLX the message which can be set to requeue messages after any time you set.
Reconnection Logic
If a service does lose connection to a service it requires persistent access to, then we need some logic to reconnect to it. We can reuse the same principles from the backing off principles we discussed at the outset. If we cannot connect, try again after a time, then try again after a bit longer, and so on. Simple right?
But when your app boots fresh for the first time, it also needs logic to establish anything it needs in those services. For example, if you have a queue consumer service that maintains a connection to RabbitMQ, when it boots, it needs logic in there to assert all the queues and exchanges it needs. Often, because a queue publisher service has been written previously, **that **service contains all the assert logic. However, when it comes to deploying the queue consumer service, you hit errors because the publisher service was not deployed previously and therefore had not asserted the exchanges and queues the consumer needs. This creates deployment dependencies, which trust me, you don’t want.
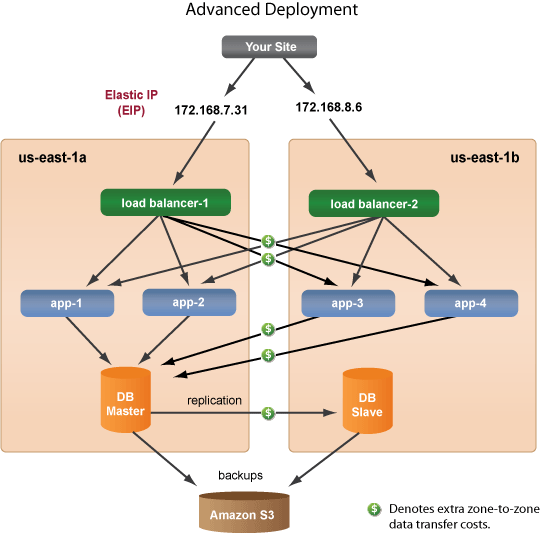 Example structure of an app with fail over
Example structure of an app with fail over
Infrastructure Failover
Of course, no matter how much code you write to cope with services being down will have no bearing if your whole server goes down. With the advent of AWS, Azure and GCP, many consider this a thing of the past (99.99% is basically 100% right?), despite this, these services *will *go down. It is essential then to configure automatic failover, unless you enjoy getting woken up at 4am to redeploy an entire environment to another region.
Maybe the entire server doesn’t go down though, it could be that the app is just crashing and you need to restart the container or maybe even the entire server to get it to startup again. In these cases, auto heal mechanisms should be put in place. These mechanisms can restart the service or in some cases, redeploy it elsewhere, should it go down in the primary zone.
Be wary of distributed monoliths
The world of microservices is taking over. The potential it creates in terms of flexibility and reusability are incredible — hence why it is so widely used. Nonetheless, they come with their own trade offs, namely in the structure of them.
One of the main arguments you hear in favour of microservices is that means you no longer have one monolith you are dependant on — like the Death Star for the Sith. But when designing their microservices architecture, the services are just daisy chained together and completely reliant on each other. To negate this, make sure your microservices are exactly that, microscopic. Be wary of clusters of microservices that share a data store, or when changes to one service requires a redeployment of another. Most importantly of all, ensure that the services can scale independently of one another.
Building resilient services can be a challenge and it does take time. Even just configuring the auto availability zone failover in AWS took a long time and consideration by some talented engineers to solve. Like with anything, there is quick wins and acceptable known faults in the system. If you don’t have time to configure auto heal and failovers, make sure you have a process written so anyone can do it manually. They all aid to delivering a optimal system and reliable user experience, but most importantly, you can sleep soundly without getting called up, safe in the knowledge all your servers are humming along nicely.
Let me know any other tips you have for creating resilience in systems!